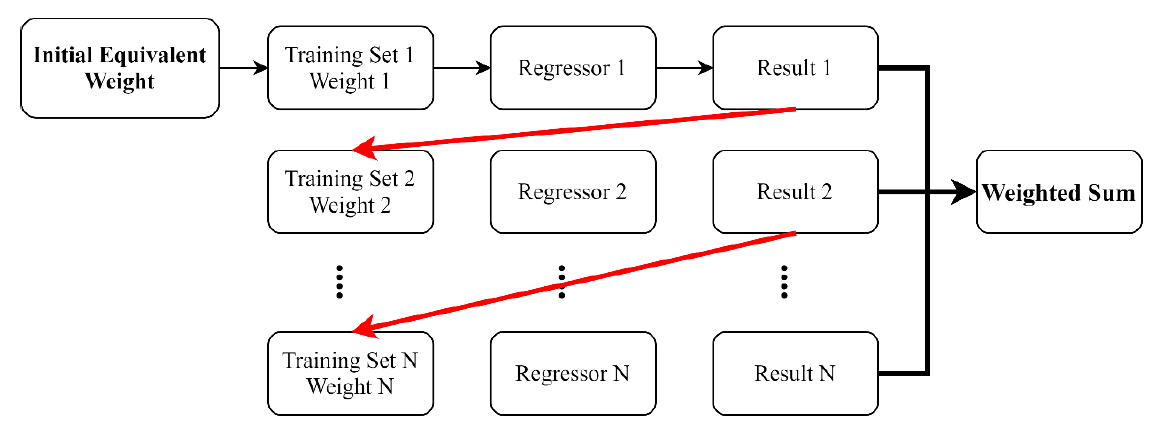
Gradient Boosting Regressor
Gradient Boosting Regressor is an iterative decision tree integration method. The Boosting method used is to first create a weak learner (which is Decision Tree). After fitting the data set and calculating its prediction residuals, the next weak learner is made to learn the residuals. The larger the residuals, the greater the weight. This step is repeated until the preset number of times is reached or the residual reaches the set value, and then the result of each weak learner is accumulated according to the weight as the final prediction. Since each weak learner is based on the result of the previous one, the classifier cannot be manufactured in parallel, so the analysis speed is slower. In addition, if the Boosting method is used on data with many errors, the effect will be poor, the reason is that each learner will learn the residual of the previous learner, if the cause of the previous residual is caused by incorrect data, the error will continue to be learned and cause the weight to be amplified, making the algorithm continue to move closer to the error, and ultimately produce incorrect predictions.
The advantages of Gradient Boosting Regressor include:
1.The accuracy of the analysis results is extremely high.
2.Both regression and classification problems are applicable.
3.There are many adjustable parameters of the model.
4.The impact of missing values is small.
5.The data does not require feature scaling.
The disadvantages of Gradient Boosting Regressor include:
1.There are many parameters to be adjusted, and it is not easy to find the best parameters.
2.Prone to overfit.
3.The analysis result is more difficult to understand than the bagging method.
4.Not suitable for data with a small amount of data.
5.Each learner is related to each other and cannot be manufactured at the same time, so it takes a long time.
6.Very sensitive to error values.
Gradient Boosting Regressor是一種迭代的決策樹集成方法,其所使用的Boosting方法是透過先製造出一個弱學習器(此為Decision Tree),對數據集進行擬合並計算出其預測殘差後,製造出下一個弱學習器來對此殘差再進行學習,殘差越大則代表權重越大。此步驟重複至達到預設次數或殘差達到設定數值後,再將每個弱學習器的結果依權重累加作為最終的預測。由於每一個弱學習器是基於前一個的結果,分類器不可並行製造,故分析速度較慢。此外,Boosting方法如用於含有較多錯誤的數據上效果將較差,原因為每一個學習器都會對前一個學習器的殘差進行學習,若前一個殘差之成因是由錯誤數據所造成,此錯誤將不斷被學習而導致權重放大,使演算法不斷向錯誤靠攏,最終產生錯誤的預測。
Gradient Boosting Regressor的優點包括:
1.分析結果準確度極高。
2.回歸與分類問題皆適用。
3.模型可調整參數多。
4.缺失值影響較小。
5.資料不需進行特徵縮放。
Gradient Boosting Regressor的缺點包括:
1.須調整之參數量多,不易找到最佳參數。
2.易過擬合。
3.分析結果較bagging方法又更難理解。
4.不適合應用於數據量較少的資料。
5.每個學習器之間有前後關聯,無法同時製造因此所需花費時間較長。
6.對錯誤值非常敏感。