Decision Tree
Decision Tree is one of the common data mining techniques, and it is the basis of many machine learning algorithms. It uses the concept of tree branching as the decision model. It is a powerful, intuitive process, and highly efficient supervised machine learning model. Decision Tree is called a classification tree if it is used for classification, and it is called a regression tree if it is used for a continuous function. The reason Decision Tree is very popular in the field of data mining is that it uses simple rules to regress data without requiring extensive calculations, and whether it is categorical or continuous data, decision trees can be used for analysis.
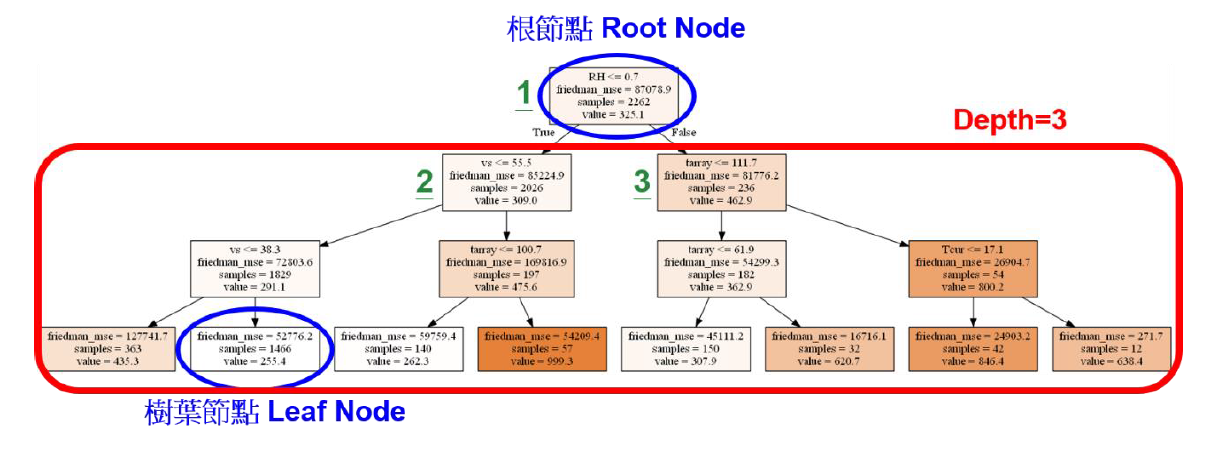
The method of Decision Tree is to start from the root node of the uppermost layer, according to the setting of the number of learner layers, and divide it sequentially from top to bottom, the method is completed after reaching the leaf node of the lowermost layer. Each node has a determination of parameters. When the determination is correct, it will branch to the lower left, and when it is wrong, it will branch to the lower right. For example, if root node number 1 is observed, it can be found that the dividing condition of whether the relative humidity (RH) is less than or equal to 0.7, if the relative humidity is less than or equal to 0.7, it will be divided to the bottom left node number 2, and when the relative humidity is greater than 0.7, it will be divided to the bottom right node number 3. The method of selecting parameters for each node to divide is to analyze all the parameters and their values, and select the parameters and values that can optimize the prediction results for division. This research is a regression analysis, so the way to determine the optimization is to find the configuration with the lowest mean square error (MSE)
The advantages of Decision Tree include:
1.The analysis results are intuitive and easy to understand.
2.The data preprocessing steps are simple.
3.Insensitive to missing values.
4.No need to normalize the data first.
The disadvantages of Decision Tree include:
1.It is a single learner algorithm, and its prediction accuracy is lower than that of the integrated method.
2.When the target value changes, the decision tree may change dramatically.
3.It is a single algorithm and is less suitable for the prediction of continuous function.
Decision Tree是常見的資料探勘技術之一,且為許多機器學習演算法之基礎,其使用樹狀分枝的概念作為決策模式,是一種強大、過程直覺單純、執行效率相當高的監督式機器學習模型。Decision Tree如使用在分類上稱為分類樹(classification tree),使用在連續函數上稱為迴歸樹(regression tree)。Decision Tree在資料探勘領域中非常受歡迎的原因為,其應用簡單規則對資料進行回歸,不需經過龐大的運算,且無論是類別型或連續型資料皆可以使用決策樹進行分析。
Decision Tree的訓練方法為從最上層根節點(root node)出發,依據學習器層數設定,由上至下依序進行分割,待達到最下層之樹葉節點(leaf node)後訓練完畢。每一節點皆有一項參數判定,當判定為正確時,往左下進行分支,為錯誤時,向右下進行分支。舉例而言,若觀察根節點編號1,可發現其劃分條件為相對溼度(RH)是否小於等於0.7,若相對溼度小於等於0.7時向左下節點編號2分割,當相對溼度大於0.7時向右下節點編號3分割。各節點選擇參數進行劃分之方法為,對所有參數與其數值進行分析,選擇能使預測結果最佳化之參數與數值進行分割。本研究為迴歸分析,故判定最佳化之方式為尋找均方誤差(MSE)最低之配置。
Decision Tree的優點包括:
1.分析結果直觀易理解。
2.資料預處理步驟簡單。
3.對缺失值不敏感。
4.不須對數據先行正規化。
Decision Tree的缺點包括:
1.為單一學習器演算法,預測準確度較集成方法低。
2.當目標數值變動時,決策樹可能有巨大改變。
3.為單一演算法,較不適合用於連續函數預測。