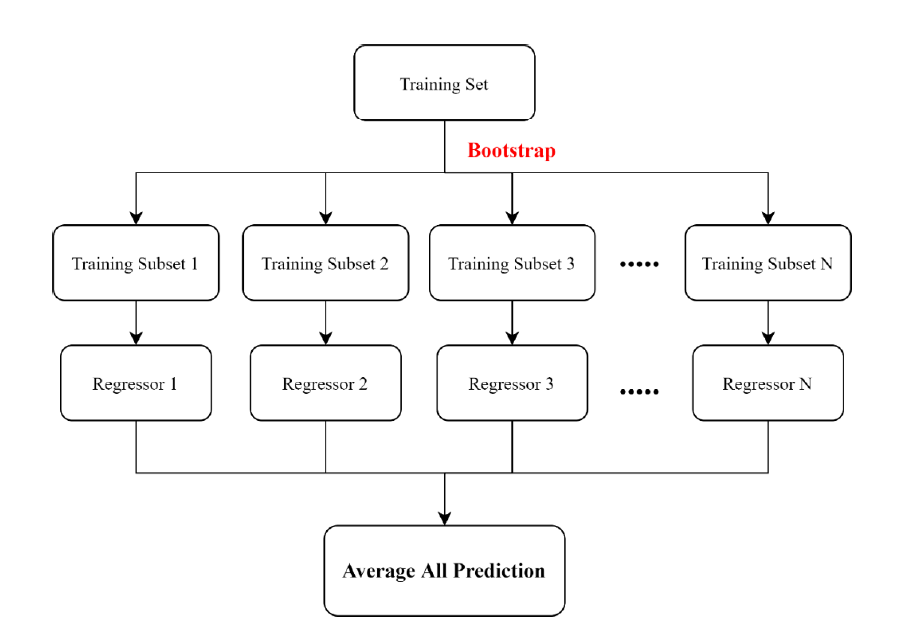
Random Forest
Random Forest is an integrated method composed of many Decision Trees, combined with randomly distributed training data (Bagging, bootstrap aggregating). The core concept of the integration method is that if the accuracy of each learner (Decision Tree) is greater than 0.5, and there are differences between each learner, by combining these learners, its performance will be better than a single learner. Through bagging, the model can be better trained from the differences in the data itself. Assuming that each learner uses N samples for training, these N samples will be randomly selected from the training set and can be repeatedly selected. This makes the total number of samples used by each learner the same, but the sample composition is different. Therefore, the trained learners are different. In regression analysis, Random Forest takes the average of all the predicted values of Decision Tree as the predicted value. Since each learner in Random Forest is independent and unrelated, the learners can be generated in parallel, and the analysis speed is faster than the Boosting method.
The advantages of Random Forest include:
1.The overfitting is less serious.
2.Both regression and classification problems are suitable for use.
3.The data does not require feature scaling.
4.The impact of missing values is small.
5.The analysis result is relatively stable.
6.The prediction accuracy is high.
The disadvantages of Random Forest include:
1.The model training time is longer, but faster than the Boosting method.
2.Random Forest is composed of multiple Decision Trees, and the result is not easy to understand.
Random Forest是由許多Decision Tree組成的集成方法,並結合隨機分配的訓練資料(Bagging, bootstrap aggregating)。集成方法的核心概念為,若每一個學習器(Decision Tree)的準確度大於0.5,且各個學習器間具有差異性,透過將這些學習器組合,其表現會優於單個學習器。透過Bagging可使模型從資料本身的差異中得到更好的訓練。假設每一個學習器皆使用N個樣本進行訓練,此N個樣本將由訓練集中隨機抽取,且可被重複挑選,此舉使每個學習器使用的總樣本數量相同,但樣本組成不同,因此訓練出的學習器才有差異。迴歸分析上,Random Forest的是將所有Decision Tree的預測數值取平均作為預測值。由於Random Forest中每一個學習器皆是獨立並無關聯的,因此學習器是可以並行生成,分析速度較Boosting方法快。
Random Forest的優點包括:
1.過擬合較不嚴重。
2.回歸及分類問題皆適合使用。
3.資料不須進行特徵縮放。
4.缺失值之影響較小。
5.分析結果較穩定。
6.預測準確度高。
Random Forest的缺點包括:
1.模型訓練時間長,但較Boosting方法快。
2.Random Forest為多個Decision Tree組成,結果較不易理解。